Source Code Deep Dive

Инженерам приходится читать исходный код. Кому-то чаще, кому-то реже, но в конце-концов приходится всем. Недостаточно знать синтаксис языка, нужно уметь быстро найти интересующую часть кода и понять пути выполнения программы.
В этой статье я расскажу об инструментах, которые помогут в этом деле. Но сначала хочется определиться с тем, когда пора погружаться.
Пора
Обычно работа на вакансии админа/девопса/сре довольно стандартна. Она состоит из чтения документации к различному софту, подбора решения под задачи, деплоя и эксплуатации. При эксплуатации, или во время внедрения, возникает больше вопросов, чем в документации есть ответов. Система исследуется дополнительно как черный ящик: выдвигается предположение, и проверяется эмпирически через изменение конфигурации/подаваемых данных/среды выполнения/и т.п.
Такой метод универсален, в этом его плюс. С ростом опыта и теоретической базы эффективность инженера повышается, он привыкает исследовать черные ящики, по описанию архитектуры может прикинуть предполагаемые узкие места и пределы работы. Но, в некоторых случаях, поиск ответа таким путём может занимать очень много времени.
Триггером может быть что угодно: неожиданная реакция на команды/конфигурацию, кажущиеся баги, лаги. Поиск возможностей для тюнинга – целая отдельная тема.
В такой ситуации можно смело задать вопрос разработчикам софта. К сожалению, они тоже люди. У них может быть очень много работы, семья, отпуск, дети, пляж, ковид. Может быть что угодно, из-за чего они смогут дать ответ тогда, когда уже будет поздно. А ещё и задать вопрос бывает реально сложно.
В результате дешевле по времени погрузиться в исходный код программы инженеру эксплуатации и понять уже в чем там дело. А там всегда ждут чудеса. Часто абстракции реализуются в коде вовсе не так, как представляется после чтения доки, а киллер-фича оказывается страшным костылём.
Здесь хочется предостеречь инженера. Работа с исходным кодом – это не просто. Да, иногда можно за 15 минут понять очень важный момент работы программы. Но все проекты разные. Какие-то большие, какие-то плохо структурированы, а какие-то разработаны академиками и используют большое количество специфичных для языка абстракций. Иногда найти корень проблемы очень трудно. Иногда это даже сложно сделать команде разработчиков этого софта, что можно говорить об одиноком инженере со стороны? Поэтому важно развивать в себе понимание того, когда пора прекратить.
Схема
Смело берём за правило: как только открыли исходник и видим, что нужно проглядеть больше одной функции – начинаем накидывать графическое отображение кода. Запомнить всё сразу в новом софте невозможно, держать большой контекст в голове – мучение. Поэтому важно отрисовать вызовы функций, которые нас интересуют в виде блок-схем.
Здесь не важно придерживаться какого-то строгого формата отображения, главное, чтобы рисующему было понятно что происходит. При этом, желательно сразу копировать линки на исходный код, чтобы была возможность от схемы перейти к нужной части кода. Я использую для этого diagrams.net. Простейшая схема может выглядить так:
А более сложная так:
Схема не должна быть полной, покрывающей весь исходный код вокруг точки входа. Достаточно описывать основные моменты, наиболее интересные нам именно сейчас. Т.е. при отслеживании изменений в какой-то структуре данных, можно начать с описания этой структуры и функций, взаимодействующих с ней. Скорее всего нам интересны пара контекстов, в пределах которых структура изменяется. Не нужно ставить перед собой задачи полностью отрисовать все взаимодействия в коде. Это сложно, затратно и ненужно.
А вот так, например, выглядит инкремент счётчика run_delay у треда, вызываемый из функции sched_info_arrive, вызываемой из sched_info_switch в контексте prepare_task_switch внутри context_switch в ядре Linux:
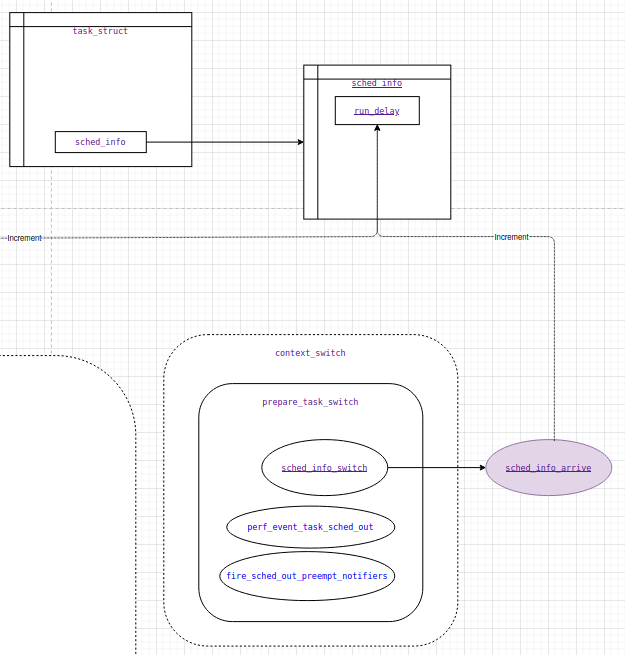
Важно отмечать абстракции, которые используются в коде. Любым удобным способом. Основная задача – запечатлеть интересующую часть кода на текущий момент, чтобы не держать всё в голове.
Да, можно назвать это бардаком. Возможно читателю будет не очень понятно, что изображено конкретно здесь и почему именно так. Но факт в том, что ориентироваться в коде становится сильно проще если отрисовать схему взаимодействия компонентов — функций и структур данных. К схеме можно даже вернуться позже и быстро восстановить мысленный контекст.
main()
Заходить в код незнакомой программы с функции main() почти всегда бесполезно. Это нужно только тогда, когда нас интересует инициализация программы, но в общем — не наш путь.
Ошибки
Ошибки — это хорошо. Это наш проводник в исходный код. Если софт пишет в лог ошибку, или жалуется в стдерр на команду, то можно взять текст ошибки и как следует грепнуть исходники. То же самое касается всех записей в логах вообще.
В идеальном случае выше по коду мы сразу увидим, что вызвало ошибку. Но может оказаться, что к ошибке ведут разные пути. Можно попробовать почитать код, прикинуться процессором, определить какой путь нас интересует. Но обычно быстрее снять сэмплы стэка по событию, либо по таймеру.
Чуть удобнее, чем grep – это vgrep. Как минимум, искать описание функции приятнее, можно быстро открыть нужный файл. Для работы с кодом на C/C++ есть cscope, но он более тяжеловесный и требует освоения.
Трейсбэк
Круче, чем ошибка — это коллтрэйс. Стэк вызовов выворачивает матрешку вызовов функций. Для нас – это способ лучше понять путь, который прошёл процессор по коду, а значит лучше понять состояние программы на момент сбоя.
В исходнике можно найти все указанные в трейсе функции и увидеть как шел процесс обработки запроса. Иногда этого достаточно, чтобы определить неверное значение где-то среди переменных, или необработанный крайний случай.
Очевидный и неприятный момент – коллтрэйс не покажет вызовы функций, которые влияют на обрабатываемый запрос, но завершили выполнение до дампа стэка. Т.е. если в одной функции вызывается подряд 10 других и в 10й программа упала и выкинула трейс, то в нём мы увидим только вызов основной функции и этой 10й функции, хотя проблема может заключаться в неверной обработке данных где-то среди оставшихся 9 функций.
Для снятия трейсов не обязательно ждать аварии. Можно использовать инструменты для анализа, такие как perf или bpftrace.
Коллтрейс с perf/bpftrace
Коллтрейс можно снимать либо по вызову конкретной функции, либо периодически через заданный интервал. Первый вариант хорошо заходит, если мы хотим получить путь кода до вызываемой функции, которую мы знаем. Второй вариант подходит в общем случае, когда мы хотим понять что у нас работает в системе в целом.
За тем и другим нужно смотреть документацию. Здесь важно, что если количество событий большое, то и вывод на экран может быть здоровый и можно зааффектить клиентскую нагрузку. Поэтому нужно как-то мержить записи и не принтать на экран каждый вызов. С bpftrace это можно сделать, например, так:
~# bpftrace -e 'k:tcp_sendmsg {@[kstack] = count();} i:s:1 {print(@); clear(@);}'
Attaching 2 probes...
@[
tcp_sendmsg+1
sock_sendmsg+92
sock_write_iter+147
new_sync_write+293
__vfs_write+41
vfs_write+177
ksys_write+167
__x64_sys_write+26
do_syscall_64+87
entry_SYSCALL_64_after_hwframe+68
]: 1
@[
tcp_sendmsg+1
sock_sendmsg+92
____sys_sendmsg+512
___sys_sendmsg+136
__sys_sendmsg+99
__x64_sys_sendmsg+31
do_syscall_64+87
entry_SYSCALL_64_after_hwframe+68
]: 2181
...
Здесь у нас видно два пути вызова tcp_sendmsg: один случился всего раз, а другой 2181 раз. При этом вывод на экран мы получили не на каждый вызов, а по таймеру, спустя секунду после запуска. Это более эффективный способ, чем дампить каждый вызов функции.
Для нормальной работы отладчика и профилировщика нужна информация об адресах функций. Такая информация может быть доступна из фрейм поинтера, для этого софт нужно собрать с флагом
-fno-omit-frame-pointer. Но это может сказаться на производительности приложения. Другой вариант – использовать отладочные символы. Если сборка своя – можно не вырезать символы из бинаря (не вызыватьstripв процессе сборки), тогда растет размер файла, но зато пользоваться этим удобнее всего. Можно собирать отладочные символы в отдельный пакет, так поступают многие мейнтейнеры софта в популярных дистрибутивах.perfможет использовать dwarf с аргументом--call-graph dwarf.
При сэмплировании стэка по таймеру рекомендуется задавать частоту сэмплирования (-F для perf), равную какому-нибудь не круглому число. Например, 199. Смысл в том, что есть риск нарваться на какую-то задачу, которая выполняется с частотой запуска профилировщика. Большинство таймеров в системе заданы программистами, а они чаще используют круглые или кратные 5 числа. Подробнее про perf я уже писал на хабре. За отличными примерами по perf можно пойти на сайт Брендана Грегга. Если какая-то функция отрабатывает быстро и её контекст не находится на стэке в момент работы профилировщика, то её мы не увидим.
kprobes/uprobes
Если мы знаем название функции и хотим понять, например, аргументы вызова этой функции или частоту вызова, то можно использовать те же инструменты, что и выше. На самом деле, в предыдущем примере я уже использовал ядерную пробу (kprobe).
Довольно подробно на примере bcc я уже писал про использование проб для получения инфы из структур ядра.
Пробы работают примерно так же, как отладчик, используя механизм точек останова. Первые байты инструкции, на которую навешана проба, заменяются точкой останова. При вызове точки останова, срабатывает ловушка и выполнение переходит в bpf-программу, которую мы подготовили. Если хочется понять детали, то стоит почитать документацию. Вкратце, как обычно – никакой магии, всё по чертежу.
Тут тоже не всё так гладко. Бывает, что хочется получить информацию о функции, но она оказывается заинлайнена во время компиляции. Это значит, что компилятор просто вписывает код функции во все места, где она вызывается в исходнике. Так удается избежать процедуры вызова функции с сохранением контекста и передачей аргументов. Делается это за счет роста размера исполняемого файла, поэтому популярно для маленьких функций. В качестве воркэраунда можно попробовать выяснить адреса в памяти, где находятся интересующие части кода и использовать perf для установки брейкпоинта на событие запуска кода из этого места, или на чтение данных из другого места, например, интересующей переменной. Но выяснить адрес переменной иногда бывает действительно трудно.
gdb
Отладчик создан для отладки. Использовать gdb на продакшене рискованно, потому что он легко вызывает фризы программы.
На проде можно использовать не интерактивный режим работы gdb в некоторых случаях. Но бывает такое, что отладчик фейлится и процесс остается висеть в статусе paused. Это конечно недопустимо:)
>$ sudo gdb -p 2004 -q --batch -ex 'thr app all bt full'
[New LWP 2007]
[New LWP 2008]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f1bc4206cf9 in __GI___poll (fds=0x56040cf57800, nfds=7, timeout=-1) at ../sysdeps/unix/sysv/linux/poll.c:29
29 ../sysdeps/unix/sysv/linux/poll.c: No such file or directory.
Thread 3 (Thread 0x7f1bbbfff700 (LWP 2008)):
#0 0x00007f1bc4206cf9 in __GI___poll (fds=0x7f1bb400c5a0, nfds=5, timeout=-1) at ../sysdeps/unix/sysv/linux/poll.c:29
resultvar = 18446744073709551100
sc_cancel_oldtype = 0
#1 0x00007f1bc52546e9 in () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#2 0x00007f1bc5254a82 in g_main_loop_run () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#3 0x00007f1bc58422d6 in () at /usr/lib/x86_64-linux-gnu/libgio-2.0.so.0
#4 0x00007f1bc527c2a5 in () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#5 0x00007f1bc44ea6db in start_thread (arg=0x7f1bbbfff700) at pthread_create.c:463
pd = 0x7f1bbbfff700
now = <optimized out>
unwind_buf = {cancel_jmp_buf = {{jmp_buf = {139757094958848, 8678067557208934083, 139757094956544, 0, 94575396732144, 140721220090416, -8765755809032845629, -8765912620801472829}, mask_was_saved = 0}}, priv = {pad = {0x0, 0x0, 0x0, 0x0}, data = {prev = 0x0, cleanup = 0x0, canceltype = 0}}}
not_first_call = <optimized out>
#6 0x00007f1bc4213a3f in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
Thread 2 (Thread 0x7f1bc0f4d700 (LWP 2007)):
#0 0x00007f1bc4206cf9 in __GI___poll (fds=0x56040ceded90, nfds=1, timeout=-1) at ../sysdeps/unix/sysv/linux/poll.c:29
resultvar = 18446744073709551100
sc_cancel_oldtype = 0
#1 0x00007f1bc52546e9 in () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#2 0x00007f1bc52547fc in g_main_context_iteration () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#3 0x00007f1bc5254841 in () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#4 0x00007f1bc527c2a5 in () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#5 0x00007f1bc44ea6db in start_thread (arg=0x7f1bc0f4d700) at pthread_create.c:463
pd = 0x7f1bc0f4d700
now = <optimized out>
unwind_buf = {cancel_jmp_buf = {{jmp_buf = {139757178115840, 8678067557208934083, 139757178113536, 0, 94575396731984, 140721220090032, -8765920642361473341, -8765912620801472829}, mask_was_saved = 0}}, priv = {pad = {0x0, 0x0, 0x0, 0x0}, data = {prev = 0x0, cleanup = 0x0, canceltype = 0}}}
not_first_call = <optimized out>
#6 0x00007f1bc4213a3f in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
Thread 1 (Thread 0x7f1bc5ef5900 (LWP 2004)):
#0 0x00007f1bc4206cf9 in __GI___poll (fds=0x56040cf57800, nfds=7, timeout=-1) at ../sysdeps/unix/sysv/linux/poll.c:29
resultvar = 18446744073709551100
sc_cancel_oldtype = 0
#1 0x00007f1bc52546e9 in () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#2 0x00007f1bc5254a82 in g_main_loop_run () at /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#3 0x000056040b9d83b4 in ()
#4 0x00007f1bc4113b97 in __libc_start_main (main=0x56040b9d7fc0, argc=1, argv=0x7ffc3655fdb8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7ffc3655fda8) at ../csu/libc-start.c:310
result = <optimized out>
unwind_buf = {cancel_jmp_buf = {{jmp_buf = {0, -3141639837352212797, 94575374730720, 140721220091312, 0, 0, -8676504790378232125, -8765913260049709373}, mask_was_saved = 0}}, priv = {pad = {0x0, 0x0, 0x7f1bc5d26783 <_dl_init+259>, 0x7f1bc5201a58}, data = {prev = 0x0, cleanup = 0x0, canceltype = -976066685}}}
not_first_call = <optimized out>
#5 0x000056040b9d860a in ()
Но если известно как воспроизводить проблему, то на тестовых стендах gdb — это отличный инструмент. Можно буквально пошагово идти по коду и проверять состояния переменных. Да можно даже менять значения переменных и смотреть чем это закончится! И вызывать функции, например, из стандартной библиотеки. Можно убить процесс-зомби, вызвав waitpid() внутри какого-нибудь процесса-донора.
В конце-концов
Работать с исходным кодом сложно, но иногда нужно.
Для эффективной работы надо знать синтаксис языка, ориентироваться в рантайме, уметь пользоваться специфичными инструментами и знать когда пора остановиться. Это дает мощные преимущества при решении задач, но и требует больших затрат на старте.
Всегда рисуйте схему. Графическое изображение кода – очень удобный инструмент, позволяющий чуть больше расслабиться при решении такой сложной задачи, как поиск проблемы в коде.
Ищите любой способ уточнить какую часть кода нужно исследовать. Ошибки, трейсы, отладчик – наши лучшие друзья в этом деле. Используйте современные инструменты и не бойтесь неизвестного.